4 months ago
Lokale LLMs im Unternehmen: Open-Source-Modelle wie Mistral und Codestral auf eigener Hardware. Kein Datenschutz-Problem, keine API-Kosten, volle Kontrolle. Wir haben einen internen Playground gebaut wo jedes Team die Modelle für ihre Use Cases testen kann.
Die überraschende Erkenntnis: Für 80% unserer Anwendungsfälle reicht ein 13B-Modell. Nur für komplexe Analyse und Coding brauchen wir die großen Modelle. #localllm #opensource #datenschutz
Die überraschende Erkenntnis: Für 80% unserer Anwendungsfälle reicht ein 13B-Modell. Nur für komplexe Analyse und Coding brauchen wir die großen Modelle. #localllm #opensource #datenschutz


4 months ago
LLM-basierte Dokumentations-Pipeline aufgebaut: Technische Specs rein, strukturierte API-Docs raus. Die Qualität ist beeindruckend - Chain-of-Thought-Reasoning analysiert komplexe Codebasen und generiert Docs die tatsächlich korrekt und vollständig sind. Vorher: 2 Tage pro API-Modul. Jetzt: 30 Minuten Review. #llm #ai #dokumentation

4 months ago
Documentation-as-Code: Unsere technischen Docs leben jetzt im gleichen Git-Repo wie der Code. Markdown-Files, automatisch per MkDocs gerendert und bei jedem Merge deployed. Änderungen an der API? PR muss auch die Docs updaten, sonst blockiert der CI-Check.
Ergebnis nach 6 Monaten: Docs-Abdeckung von 30% auf 85% gestiegen. Neue Entwickler brauchen 50% weniger Einarbeitungszeit. Der Trick: Docs müssen genauso reviewed werden wie Code. #documentation #devops #docascode
Ergebnis nach 6 Monaten: Docs-Abdeckung von 30% auf 85% gestiegen. Neue Entwickler brauchen 50% weniger Einarbeitungszeit. Der Trick: Docs müssen genauso reviewed werden wie Code. #documentation #devops #docascode

4 months ago
Workflow Automation Playbook - Schritt-für-Schritt Anleitung zur Automatisierung von Geschäftsprozessen. 30+ fertige Workflows für n8n und Zapier. #automation #playbook

4 months ago
Monorepo mit Turborepo: Build-Zeiten von 25 Minuten auf 7 Minuten. Remote Caching auf Vercel spart nochmal 60% bei unveränderten Packages. 4 Frontend-Apps, 12 Shared-Libraries, ein einziger Dependency-Tree.
Der größte Vorteil den niemand erwähnt: Atomic Commits über alle Packages. Wenn ein API-Typ sich ändert, werden Frontend und Backend im gleichen PR angepasst. Keine Versions-Inkompatibilitäten mehr. #monorepo #turborepo #devex
Der größte Vorteil den niemand erwähnt: Atomic Commits über alle Packages. Wenn ein API-Typ sich ändert, werden Frontend und Backend im gleichen PR angepasst. Keine Versions-Inkompatibilitäten mehr. #monorepo #turborepo #devex
4 months ago
RAG-Pipeline mit lokalem LLM on-premise aufgesetzt - kein Cloud-API, DSGVO-konform. Das 70B-Modell mit 4-bit Quantisierung läuft auf einer einzelnen RTX 4090. Die Ergebnisse bei firmeninternen Dokumenten sind erstaunlich gut.
Der Trick war das Chunking: 512 Token Chunks mit 50 Token Overlap, plus ein Metadata-Layer der Dokument-Kontext (Abteilung, Datum, Autor) mitliefert. Retrieval-Genauigkeit liegt bei 94% auf unserem internen Benchmark. Kosten: Einmalig 1.800 EUR für die GPU statt 2.000 EUR/Monat für API-Calls. #ai #rag #datenschutz #llm
Der Trick war das Chunking: 512 Token Chunks mit 50 Token Overlap, plus ein Metadata-Layer der Dokument-Kontext (Abteilung, Datum, Autor) mitliefert. Retrieval-Genauigkeit liegt bei 94% auf unserem internen Benchmark. Kosten: Einmalig 1.800 EUR für die GPU statt 2.000 EUR/Monat für API-Calls. #ai #rag #datenschutz #llm

4 months ago
AI Agents mit Tool-Orchestrierung gebaut: Unsere Support-Agenten greifen jetzt über standardisierte API-Interfaces auf CRM, Ticketing und Wissensdatenbank zu. Ein Agent löst 73% der Anfragen automatisch - 25 Prozentpunkte besser als der einfache Chatbot davor.
Der Durchbruch war die Tool-Orchestrierung: Der Agent entscheidet selbst welche Datenquellen er braucht, ruft sie über definierte Schnittstellen ab und kombiniert die Ergebnisse kontextbezogen. #aiagents #tooluse #kundenservice
Der Durchbruch war die Tool-Orchestrierung: Der Agent entscheidet selbst welche Datenquellen er braucht, ruft sie über definierte Schnittstellen ab und kombiniert die Ergebnisse kontextbezogen. #aiagents #tooluse #kundenservice

4 months ago
AI Agents mit Tool-Orchestrierung gebaut: Unsere Support-Agenten greifen jetzt über standardisierte API-Interfaces auf CRM, Ticketing und Wissensdatenbank zu. Ein Agent löst 73% der Anfragen automatisch - 25 Prozentpunkte besser als der einfache Chatbot davor.
Der Durchbruch war die Tool-Orchestrierung: Der Agent entscheidet selbst welche Datenquellen er braucht, ruft sie über definierte Schnittstellen ab und kombiniert die Ergebnisse kontextbezogen. #aiagents #tooluse #kundenservice
Der Durchbruch war die Tool-Orchestrierung: Der Agent entscheidet selbst welche Datenquellen er braucht, ruft sie über definierte Schnittstellen ab und kombiniert die Ergebnisse kontextbezogen. #aiagents #tooluse #kundenservice

4 months ago
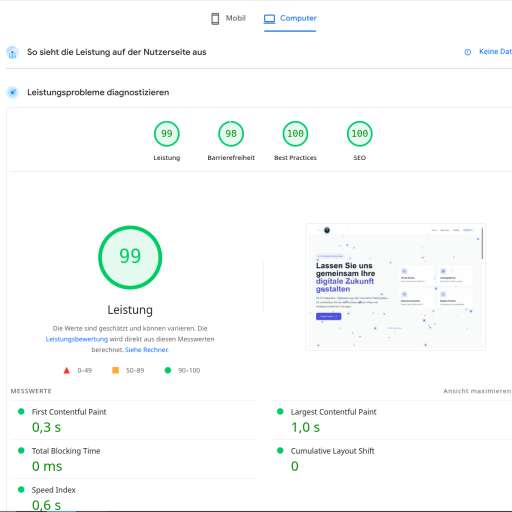
CDN-Konfiguration komplett überarbeitet. TTFB von 800ms auf 120ms für globale User. Die Maßnahmen: Edge-Caching für statische Assets (30 Tage), stale-while-revalidate für API-Responses, Brotli-Kompression statt Gzip. Besonders beeindruckend: User in Asien berichten von 3x schnelleren Ladezeiten. #cdn #performance #global

4 months ago
Automatische Bewässerung v2.0 fertig: ESP32-S3, 4 kapazitive Bodenfeuchtesensoren, Magnetventile, Solarpanel. Das System entscheidet selbst wann und wie lange bewässert wird - basierend auf Bodenfeuchte, Wettervorhersage (API-Abfrage alle 6h) und Pflanzenprofilen.
Wasserverbrauch gegenüber Zeitschaltuhr um 45% reduziert. Pflanzen sehen besser aus als je zuvor. Alles per MQTT an Home Assistant angebunden, Verlauf in Grafana. Das vollständige Tutorial kommt nächste Woche. #smarthome #esp32 #automation
Wasserverbrauch gegenüber Zeitschaltuhr um 45% reduziert. Pflanzen sehen besser aus als je zuvor. Alles per MQTT an Home Assistant angebunden, Verlauf in Grafana. Das vollständige Tutorial kommt nächste Woche. #smarthome #esp32 #automation


5 months ago
n8n statt Zapier: Open Source, self-hosted auf einem kleinen VPS (9 EUR/Monat), DSGVO-konform, keine Datenweitergabe an Dritte. 47 Workflows automatisieren alles von Lead-Nurturing über Slack-Notifications bis zur Rechnungsverarbeitung. Spart dem Team 10+ Stunden pro Woche. Der größte Workflow: CRM-Sync zwischen 3 Tools mit Deduplizierung und Datenanreicherung. #automation #dsgvo #n8n

5 months ago
API-Design Lehre aus 3 Jahren Produktion: Versionierung von Tag 1 einplanen. Wir mussten unsere API nachträglich versionieren - das bedeutete 6 Wochen Umbau, 200+ Clients informieren und eine 3-monatige Übergangsphase mit Doppel-Support.
Was wir jetzt anders machen: URL-Versionierung (/v1/, /v2/), Deprecation-Header ab Tag 1, und ein API-Changelog der automatisch aus OpenAPI-Diffs generiert wird. Hätten wir das von Anfang an gehabt, wären uns 2 Monate Arbeit erspart geblieben. #api #backend #architektur
Was wir jetzt anders machen: URL-Versionierung (/v1/, /v2/), Deprecation-Header ab Tag 1, und ein API-Changelog der automatisch aus OpenAPI-Diffs generiert wird. Hätten wir das von Anfang an gehabt, wären uns 2 Monate Arbeit erspart geblieben. #api #backend #architektur
5 months ago
RAG-Pipeline mit lokalem LLM on-premise aufgesetzt - kein Cloud-API, DSGVO-konform. Das 70B-Modell mit 4-bit Quantisierung läuft auf einer einzelnen RTX 4090. Die Ergebnisse bei firmeninternen Dokumenten sind erstaunlich gut.
Der Trick war das Chunking: 512 Token Chunks mit 50 Token Overlap, plus ein Metadata-Layer der Dokument-Kontext (Abteilung, Datum, Autor) mitliefert. Retrieval-Genauigkeit liegt bei 94% auf unserem internen Benchmark. Kosten: Einmalig 1.800 EUR für die GPU statt 2.000 EUR/Monat für API-Calls. #ai #rag #datenschutz #llm
Der Trick war das Chunking: 512 Token Chunks mit 50 Token Overlap, plus ein Metadata-Layer der Dokument-Kontext (Abteilung, Datum, Autor) mitliefert. Retrieval-Genauigkeit liegt bei 94% auf unserem internen Benchmark. Kosten: Einmalig 1.800 EUR für die GPU statt 2.000 EUR/Monat für API-Calls. #ai #rag #datenschutz #llm

5 months ago
LLM-basierte Dokumentations-Pipeline aufgebaut: Technische Specs rein, strukturierte API-Docs raus. Die Qualität ist beeindruckend - Chain-of-Thought-Reasoning analysiert komplexe Codebasen und generiert Docs die tatsächlich korrekt und vollständig sind. Vorher: 2 Tage pro API-Modul. Jetzt: 30 Minuten Review. #llm #ai #dokumentation


5 months ago
IBM Quantum Eagle mit 1.000+ Qubits getestet: Grover-Algorithmus auf einem System das vor 2 Jahren undenkbar gewesen wäre. Die Lernkurve ist steil - quantenmechanische Intuition entwickelt man nicht über Nacht. Aber die Möglichkeiten sind faszinierend.
Konkret: Unstrukturierte Suche in einer Datenbank mit N Einträgen in O(sqrt(N)) statt O(N). Für 1 Million Einträge: 1.000 statt 1.000.000 Operationen. Die Fehlerraten sinken rapide - praktische Anwendungen rücken in greifbare Nähe. #quantum #zukunft #qiskit
Konkret: Unstrukturierte Suche in einer Datenbank mit N Einträgen in O(sqrt(N)) statt O(N). Für 1 Million Einträge: 1.000 statt 1.000.000 Operationen. Die Fehlerraten sinken rapide - praktische Anwendungen rücken in greifbare Nähe. #quantum #zukunft #qiskit


5 months ago
GraphQL nach 12 Monaten in Produktion: Over-Fetching ist Geschichte, Frontend-Team arbeitet unabhängig vom Backend. Aber - die Komplexität auf der Server-Seite ist enorm gewachsen. N+1 Queries, Autorisierung pro Feld, Query-Depth-Limiting gegen Missbrauch.
Mein Fazit: Für komplexe UIs mit vielen verschachtelten Daten ist GraphQL genial. Für einfache CRUD-APIs ist REST weiterhin die bessere Wahl. Nicht jedes Problem braucht GraphQL. #graphql #api #architektur
Mein Fazit: Für komplexe UIs mit vielen verschachtelten Daten ist GraphQL genial. Für einfache CRUD-APIs ist REST weiterhin die bessere Wahl. Nicht jedes Problem braucht GraphQL. #graphql #api #architektur
5 months ago
Monorepo mit Turborepo: Build-Zeiten von 25 Minuten auf 7 Minuten. Remote Caching auf Vercel spart nochmal 60% bei unveränderten Packages. 4 Frontend-Apps, 12 Shared-Libraries, ein einziger Dependency-Tree.
Der größte Vorteil den niemand erwähnt: Atomic Commits über alle Packages. Wenn ein API-Typ sich ändert, werden Frontend und Backend im gleichen PR angepasst. Keine Versions-Inkompatibilitäten mehr. #monorepo #turborepo #devex
Der größte Vorteil den niemand erwähnt: Atomic Commits über alle Packages. Wenn ein API-Typ sich ändert, werden Frontend und Backend im gleichen PR angepasst. Keine Versions-Inkompatibilitäten mehr. #monorepo #turborepo #devex


5 months ago
API-Design Lehre aus 3 Jahren Produktion: Versionierung von Tag 1 einplanen. Wir mussten unsere API nachträglich versionieren - das bedeutete 6 Wochen Umbau, 200+ Clients informieren und eine 3-monatige Übergangsphase mit Doppel-Support.
Was wir jetzt anders machen: URL-Versionierung (/v1/, /v2/), Deprecation-Header ab Tag 1, und ein API-Changelog der automatisch aus OpenAPI-Diffs generiert wird. Hätten wir das von Anfang an gehabt, wären uns 2 Monate Arbeit erspart geblieben. #api #backend #architektur
Was wir jetzt anders machen: URL-Versionierung (/v1/, /v2/), Deprecation-Header ab Tag 1, und ein API-Changelog der automatisch aus OpenAPI-Diffs generiert wird. Hätten wir das von Anfang an gehabt, wären uns 2 Monate Arbeit erspart geblieben. #api #backend #architektur

5 months ago
Automatische Bewässerung v2.0 fertig: ESP32-S3, 4 kapazitive Bodenfeuchtesensoren, Magnetventile, Solarpanel. Das System entscheidet selbst wann und wie lange bewässert wird - basierend auf Bodenfeuchte, Wettervorhersage (API-Abfrage alle 6h) und Pflanzenprofilen.
Wasserverbrauch gegenüber Zeitschaltuhr um 45% reduziert. Pflanzen sehen besser aus als je zuvor. Alles per MQTT an Home Assistant angebunden, Verlauf in Grafana. Das vollständige Tutorial kommt nächste Woche. #smarthome #esp32 #automation
Wasserverbrauch gegenüber Zeitschaltuhr um 45% reduziert. Pflanzen sehen besser aus als je zuvor. Alles per MQTT an Home Assistant angebunden, Verlauf in Grafana. Das vollständige Tutorial kommt nächste Woche. #smarthome #esp32 #automation
5 months ago
Kubernetes 1.32 Gateway API jetzt in Produktion - endlich ein standardisierter Ingress-Ersatz. Auto-Skalierung bei Traffic-Spitzen funktioniert brillant - Black Friday mit 10x Traffic ohne Ausfallzeit überstanden. Aber die Komplexität ist real.
Was wir unterschätzt haben: Persistent Volumes und StatefulSets sind deutlich trickreicher als Stateless-Deployments. Unsere PostgreSQL-Migration auf K8s hat 3 Anläufe gebraucht. Lesson learned: Datenbanken gehören (noch) nicht in Kubernetes, es sei denn man hat dediziertes DB-Ops-Know-how.
Was sich gelohnt hat: GitOps-Workflow mit ArgoCD, automatische Rollbacks bei fehlgeschlagenen Health-Checks, und Resource-Quotas die verhindern dass ein Team den gesamten Cluster lahmlegt. #kubernetes #devops #cloudnative
Was wir unterschätzt haben: Persistent Volumes und StatefulSets sind deutlich trickreicher als Stateless-Deployments. Unsere PostgreSQL-Migration auf K8s hat 3 Anläufe gebraucht. Lesson learned: Datenbanken gehören (noch) nicht in Kubernetes, es sei denn man hat dediziertes DB-Ops-Know-how.
Was sich gelohnt hat: GitOps-Workflow mit ArgoCD, automatische Rollbacks bei fehlgeschlagenen Health-Checks, und Resource-Quotas die verhindern dass ein Team den gesamten Cluster lahmlegt. #kubernetes #devops #cloudnative

5 months ago
API-Design Lehre aus 3 Jahren Produktion: Versionierung von Tag 1 einplanen. Wir mussten unsere API nachträglich versionieren - das bedeutete 6 Wochen Umbau, 200+ Clients informieren und eine 3-monatige Übergangsphase mit Doppel-Support.
Was wir jetzt anders machen: URL-Versionierung (/v1/, /v2/), Deprecation-Header ab Tag 1, und ein API-Changelog der automatisch aus OpenAPI-Diffs generiert wird. Hätten wir das von Anfang an gehabt, wären uns 2 Monate Arbeit erspart geblieben. #api #backend #architektur
Was wir jetzt anders machen: URL-Versionierung (/v1/, /v2/), Deprecation-Header ab Tag 1, und ein API-Changelog der automatisch aus OpenAPI-Diffs generiert wird. Hätten wir das von Anfang an gehabt, wären uns 2 Monate Arbeit erspart geblieben. #api #backend #architektur

5 months ago
Kubernetes 1.32 Gateway API jetzt in Produktion - endlich ein standardisierter Ingress-Ersatz. Auto-Skalierung bei Traffic-Spitzen funktioniert brillant - Black Friday mit 10x Traffic ohne Ausfallzeit überstanden. Aber die Komplexität ist real.
Was wir unterschätzt haben: Persistent Volumes und StatefulSets sind deutlich trickreicher als Stateless-Deployments. Unsere PostgreSQL-Migration auf K8s hat 3 Anläufe gebraucht. Lesson learned: Datenbanken gehören (noch) nicht in Kubernetes, es sei denn man hat dediziertes DB-Ops-Know-how.
Was sich gelohnt hat: GitOps-Workflow mit ArgoCD, automatische Rollbacks bei fehlgeschlagenen Health-Checks, und Resource-Quotas die verhindern dass ein Team den gesamten Cluster lahmlegt. #kubernetes #devops #cloudnative
Was wir unterschätzt haben: Persistent Volumes und StatefulSets sind deutlich trickreicher als Stateless-Deployments. Unsere PostgreSQL-Migration auf K8s hat 3 Anläufe gebraucht. Lesson learned: Datenbanken gehören (noch) nicht in Kubernetes, es sei denn man hat dediziertes DB-Ops-Know-how.
Was sich gelohnt hat: GitOps-Workflow mit ArgoCD, automatische Rollbacks bei fehlgeschlagenen Health-Checks, und Resource-Quotas die verhindern dass ein Team den gesamten Cluster lahmlegt. #kubernetes #devops #cloudnative


6 months ago
Kubernetes 1.32 Gateway API jetzt in Produktion - endlich ein standardisierter Ingress-Ersatz. Auto-Skalierung bei Traffic-Spitzen funktioniert brillant - Black Friday mit 10x Traffic ohne Ausfallzeit überstanden. Aber die Komplexität ist real.
Was wir unterschätzt haben: Persistent Volumes und StatefulSets sind deutlich trickreicher als Stateless-Deployments. Unsere PostgreSQL-Migration auf K8s hat 3 Anläufe gebraucht. Lesson learned: Datenbanken gehören (noch) nicht in Kubernetes, es sei denn man hat dediziertes DB-Ops-Know-how.
Was sich gelohnt hat: GitOps-Workflow mit ArgoCD, automatische Rollbacks bei fehlgeschlagenen Health-Checks, und Resource-Quotas die verhindern dass ein Team den gesamten Cluster lahmlegt. #kubernetes #devops #cloudnative
Was wir unterschätzt haben: Persistent Volumes und StatefulSets sind deutlich trickreicher als Stateless-Deployments. Unsere PostgreSQL-Migration auf K8s hat 3 Anläufe gebraucht. Lesson learned: Datenbanken gehören (noch) nicht in Kubernetes, es sei denn man hat dediziertes DB-Ops-Know-how.
Was sich gelohnt hat: GitOps-Workflow mit ArgoCD, automatische Rollbacks bei fehlgeschlagenen Health-Checks, und Resource-Quotas die verhindern dass ein Team den gesamten Cluster lahmlegt. #kubernetes #devops #cloudnative

6 months ago
IBM Quantum Eagle mit 1.000+ Qubits getestet: Grover-Algorithmus auf einem System das vor 2 Jahren undenkbar gewesen wäre. Die Lernkurve ist steil - quantenmechanische Intuition entwickelt man nicht über Nacht. Aber die Möglichkeiten sind faszinierend.
Konkret: Unstrukturierte Suche in einer Datenbank mit N Einträgen in O(sqrt(N)) statt O(N). Für 1 Million Einträge: 1.000 statt 1.000.000 Operationen. Die Fehlerraten sinken rapide - praktische Anwendungen rücken in greifbare Nähe. #quantum #zukunft #qiskit
Konkret: Unstrukturierte Suche in einer Datenbank mit N Einträgen in O(sqrt(N)) statt O(N). Für 1 Million Einträge: 1.000 statt 1.000.000 Operationen. Die Fehlerraten sinken rapide - praktische Anwendungen rücken in greifbare Nähe. #quantum #zukunft #qiskit
6 months ago
AI Agents mit Tool-Orchestrierung gebaut: Unsere Support-Agenten greifen jetzt über standardisierte API-Interfaces auf CRM, Ticketing und Wissensdatenbank zu. Ein Agent löst 73% der Anfragen automatisch - 25 Prozentpunkte besser als der einfache Chatbot davor.
Der Durchbruch war die Tool-Orchestrierung: Der Agent entscheidet selbst welche Datenquellen er braucht, ruft sie über definierte Schnittstellen ab und kombiniert die Ergebnisse kontextbezogen. #aiagents #tooluse #kundenservice
Der Durchbruch war die Tool-Orchestrierung: Der Agent entscheidet selbst welche Datenquellen er braucht, ruft sie über definierte Schnittstellen ab und kombiniert die Ergebnisse kontextbezogen. #aiagents #tooluse #kundenservice
6 months ago
RAG-Pipeline mit lokalem LLM on-premise aufgesetzt - kein Cloud-API, DSGVO-konform. Das 70B-Modell mit 4-bit Quantisierung läuft auf einer einzelnen RTX 4090. Die Ergebnisse bei firmeninternen Dokumenten sind erstaunlich gut.
Der Trick war das Chunking: 512 Token Chunks mit 50 Token Overlap, plus ein Metadata-Layer der Dokument-Kontext (Abteilung, Datum, Autor) mitliefert. Retrieval-Genauigkeit liegt bei 94% auf unserem internen Benchmark. Kosten: Einmalig 1.800 EUR für die GPU statt 2.000 EUR/Monat für API-Calls. #ai #rag #datenschutz #llm
Der Trick war das Chunking: 512 Token Chunks mit 50 Token Overlap, plus ein Metadata-Layer der Dokument-Kontext (Abteilung, Datum, Autor) mitliefert. Retrieval-Genauigkeit liegt bei 94% auf unserem internen Benchmark. Kosten: Einmalig 1.800 EUR für die GPU statt 2.000 EUR/Monat für API-Calls. #ai #rag #datenschutz #llm
6 months ago
CDN-Konfiguration komplett überarbeitet. TTFB von 800ms auf 120ms für globale User. Die Maßnahmen: Edge-Caching für statische Assets (30 Tage), stale-while-revalidate für API-Responses, Brotli-Kompression statt Gzip. Besonders beeindruckend: User in Asien berichten von 3x schnelleren Ladezeiten. #cdn #performance #global

6 months ago
Monorepo mit Turborepo: Build-Zeiten von 25 Minuten auf 7 Minuten. Remote Caching auf Vercel spart nochmal 60% bei unveränderten Packages. 4 Frontend-Apps, 12 Shared-Libraries, ein einziger Dependency-Tree.
Der größte Vorteil den niemand erwähnt: Atomic Commits über alle Packages. Wenn ein API-Typ sich ändert, werden Frontend und Backend im gleichen PR angepasst. Keine Versions-Inkompatibilitäten mehr. #monorepo #turborepo #devex
Der größte Vorteil den niemand erwähnt: Atomic Commits über alle Packages. Wenn ein API-Typ sich ändert, werden Frontend und Backend im gleichen PR angepasst. Keine Versions-Inkompatibilitäten mehr. #monorepo #turborepo #devex

6 months ago
Documentation-as-Code: Unsere technischen Docs leben jetzt im gleichen Git-Repo wie der Code. Markdown-Files, automatisch per MkDocs gerendert und bei jedem Merge deployed. Änderungen an der API? PR muss auch die Docs updaten, sonst blockiert der CI-Check.
Ergebnis nach 6 Monaten: Docs-Abdeckung von 30% auf 85% gestiegen. Neue Entwickler brauchen 50% weniger Einarbeitungszeit. Der Trick: Docs müssen genauso reviewed werden wie Code. #documentation #devops #docascode
Ergebnis nach 6 Monaten: Docs-Abdeckung von 30% auf 85% gestiegen. Neue Entwickler brauchen 50% weniger Einarbeitungszeit. Der Trick: Docs müssen genauso reviewed werden wie Code. #documentation #devops #docascode

6 months ago
Automatische Bewässerung v2.0 fertig: ESP32-S3, 4 kapazitive Bodenfeuchtesensoren, Magnetventile, Solarpanel. Das System entscheidet selbst wann und wie lange bewässert wird - basierend auf Bodenfeuchte, Wettervorhersage (API-Abfrage alle 6h) und Pflanzenprofilen.
Wasserverbrauch gegenüber Zeitschaltuhr um 45% reduziert. Pflanzen sehen besser aus als je zuvor. Alles per MQTT an Home Assistant angebunden, Verlauf in Grafana. Das vollständige Tutorial kommt nächste Woche. #smarthome #esp32 #automation
Wasserverbrauch gegenüber Zeitschaltuhr um 45% reduziert. Pflanzen sehen besser aus als je zuvor. Alles per MQTT an Home Assistant angebunden, Verlauf in Grafana. Das vollständige Tutorial kommt nächste Woche. #smarthome #esp32 #automation