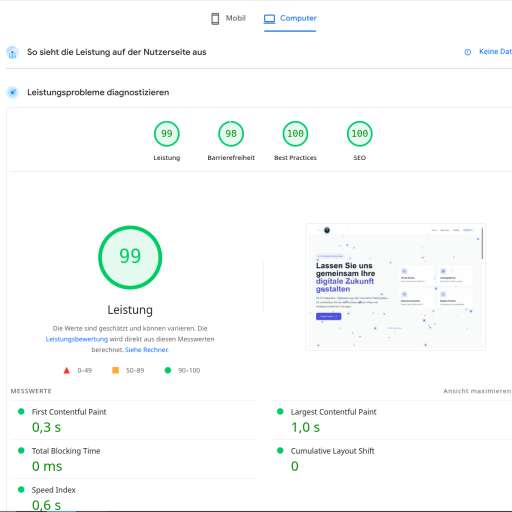
RAG-Pipeline mit lokalem LLM on-premise aufgesetzt - kein Cloud-API, DSGVO-konform. Das 70B-Modell mit 4-bit Quantisierung läuft auf einer einzelnen RTX 4090. Die Ergebnisse bei firmeninternen Dokumenten sind erstaunlich gut.
Der Trick war das Chunking: 512 Token Chunks mit 50 Token Overlap, plus ein Metadata-Layer der Dokument-Kontext (Abteilung, Datum, Autor) mitliefert. Retrieval-Genauigkeit liegt bei 94% auf unserem internen Benchmark. Kosten: Einmalig 1.800 EUR für die GPU statt 2.000 EUR/Monat für API-Calls. #ai #rag #datenschutz #llm
Der Trick war das Chunking: 512 Token Chunks mit 50 Token Overlap, plus ein Metadata-Layer der Dokument-Kontext (Abteilung, Datum, Autor) mitliefert. Retrieval-Genauigkeit liegt bei 94% auf unserem internen Benchmark. Kosten: Einmalig 1.800 EUR für die GPU statt 2.000 EUR/Monat für API-Calls. #ai #rag #datenschutz #llm
5 months ago

4 months ago
In response Nina Lorenz to her Publication
Super hilfreich! Hast du zufällig ein GitHub-Repo oder ein Beispiel-Projekt? Würde das gerne hands-on nachvollziehen.

4 months ago
In response Nina Lorenz to her Publication
Spannend! Habt ihr das auch schon unter Last getestet? Wir hatten mit einer ähnlichen Lösung Probleme ab 10.000 gleichzeitigen Verbindungen.

4 months ago
In response Nina Lorenz to her Publication
Die Lernkurve ist steil, aber es lohnt sich. Bei uns hat es ca. 4 Wochen gedauert bis das Team produktiv war. Danach ging es steil bergauf.

4 months ago
In response Nina Lorenz to her Publication
Genau solche Erfahrungsberichte braucht die Community! Theorie gibt es genug, aber echte Produktionserfahrung ist Gold wert.

4 months ago
In response Nina Lorenz to her Publication
Wie geht ihr mit dem Thema Observability um? Wir haben festgestellt dass gute Metriken und Logs die halbe Miete beim Debugging sind.