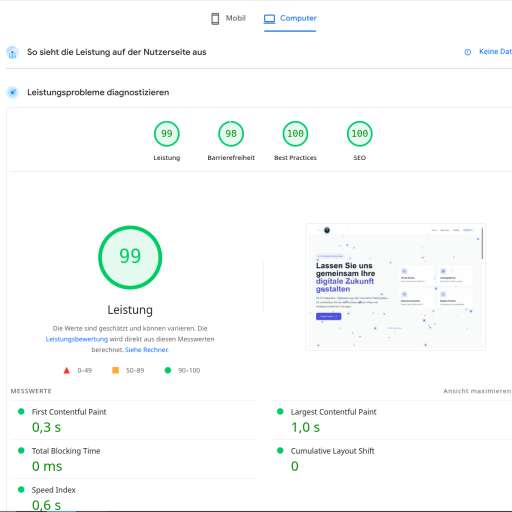
MLOps Pipeline mit MLflow + Kubeflow komplett aufgebaut. Vom Jupyter-Notebook-Chaos zu reproduzierbaren, versionierten ML-Experimenten. Jedes Training wird getrackt: Hyperparameter, Metriken, Artefakte, sogar die Git-Revision des Trainingscodes.
Model Registry mit Staging/Production-Stages, automatische A/B-Tests bei neuem Modell, und ein Rollback-Mechanismus der in unter 2 Minuten zum vorherigen Modell zurückwechselt. Endlich Ordnung im ML-Chaos. #mlops #mlflow #kubeflow
Model Registry mit Staging/Production-Stages, automatische A/B-Tests bei neuem Modell, und ein Rollback-Mechanismus der in unter 2 Minuten zum vorherigen Modell zurückwechselt. Endlich Ordnung im ML-Chaos. #mlops #mlflow #kubeflow
6 months ago

4 months ago
In response Christine Lang to her Publication
Spannend! Habt ihr das auch schon unter Last getestet? Wir hatten mit einer ähnlichen Lösung Probleme ab 10.000 gleichzeitigen Verbindungen.

4 months ago
In response Christine Lang to her Publication
Die Migration klingt aufwändig aber lohnend. Wie habt ihr den Parallelbetrieb während der Umstellung sichergestellt?

4 months ago
In response Christine Lang to her Publication
Das kann ich bestätigen. Wir sind den gleichen Weg gegangen und haben nach 6 Monaten gemessen: 30% weniger Incidents, 40% schnellere Deployments. Die Investition hat sich klar rentiert.

4 months ago
In response Christine Lang to her Publication
Wir nutzen eine ähnliche Architektur in der Produktion. Nach 12 Monaten können wir bestätigen: Die Wartungskosten sind tatsaechlich deutlich geringer.

4 months ago
In response Christine Lang to her Publication
Absolut richtig - das wird in der Branche viel zu oft unterschätzt. Ich sehe das als eine der größten Herausforderungen für 2026.